Classificação Estelar
Área de aplicação: Astronomia
Algoritmos utilizados:
- Naive Bayes
- Random Forest
- Decision Tree
- KNN
Base de dados utilizada
Sobre a base
Os dados consistem em 100.000 observações do espaço obtidas pelo SDSS (Sloan Digital Sky Survey). Cada observação é descrita por 17 colunas de características e 1 coluna de classe que a identifica como uma estrela, galáxia ou quasar.
Algumas colunas presentes no dataset:
alfa- Ângulo de ascensão retadelta- Ângulo de declinaçãou- Filtro ultravioleta no sistema fotométricog- Filtro verde no sistema fotométricor- Filtro vermelho no sistema fotométricoi- Filtro infravermelho próximo no sistema fotométricoz- Filtro infravermelho no sistema fotométricoredshift- valor do redshift com base no aumento do comprimento de onda
Pré-Processamento utilizado
Descrição da atividade
- Ao menos um método de pré-processamento deve ser usado, gerando uma nova base de dados.
- O tipo de pré-processamento utilizado deve estar relacionado ao contexto da aplicação.
- Remoção de vírgulas, espaços em branco, identificador dos padrões, etc. não serão considerados pré-processamento válidos.
MinMaxScaler:
Utilizada para dimensionar (ou normalizar) os recursos em um intervalo especifico, geralmente entre 0 e 1 ou -1 e 1
Funcionamento:
Onde:
- é o valor normalizado do recurso
- é o valor original do recurso
- é o valor mínimo do recurso
- é o valor máximo do recurso
StandardScaler
Garante que os recursos tenham uma média zero e um desvio padrão comum
Funcionamento:
Onde:
- é o valor original da característica
- é a média da característica
- é o desvio padrão da característica
Processando as bases:
# Base sem processamento
brute_X = brute_df.drop(columns=['obj_ID',
'field_ID',
'spec_obj_ID',
'fiber_ID',
'plate',
'run_ID',
'rerun_ID',
'MJD',
'class']).to_numpy()
# Classes
y = brute_df['class'].to_numpy()
# Base minMax. -1 : 1
minmax_scaler = MinMaxScaler(feature_range=(-1, 1))
minmax_X = minmax_scaler.fit_transform(brute_X)
# Base stardard
standard_scaler = StandardScaler()
standard_X = standard_scaler.fit_transform(brute_X)Execução
Descrição da atividade
- Deve-se executar o 10-fold cross-validation 5 vezes para cada base de dados, com cada uma das cinco execuções partindo de uma distribuição aleatória dos dados entre cada fold, resultando em um total de 50 experimentos por base de dados (10 x 5).
- Em cada um dos 50 experimentos, os conjuntos de treinamento e teste devem ser mantido o mesmo para cada algoritmo a ser testado (mesmo ponto de partida para cada modelo), de modo a obter-se uma avaliação justa dos resultados.
- Ao menos três algoritmos devem ser testados e comparados:
- Árvore de Decisão;
- Naïve Bayes;
- K-Vizinhos Mais Próximos (K-NN) - variando-se 3 vezes o número do parâmetro k;
- Rede Neural Artificial treinada por Backpropagation.
- Outros Algoritmos de Aprendizagem Supervisionada (Classificadores) mediante validação prévia do Professor.
Definindo condições do projeto:
seeds = [2, 4, 8, 16, 32]
folds=10
algorithms = [rf, nb, knn, dt]
databases = [brute_X, minmax_X, standard_X]seeds- garantindo que os valores ‘aleatórios’ sejam os mesmos para cada uma das 5 interaçõesfolds- quantia de folds para o cross validationalgorithms- Algoritmos utilizadosRandomForest()NaiveBayes()KNN()DecisionTree()
Executando:
Código resumido
Visando evitar excesso de informação no bloco de código, todas as linhas coletando dados (tempos de execução e tratamento dos scores) foram removidas deste resumo
# Para cada base de dados (brute_X, processed_X)
for index, X in enumerate(databases):
# Ao menos três algoritmos devem ser testados e comparados
for algorithm in algorithms:
# Cinco execuções partindo de uma distribuição aleatória
# dos dados entre cada fold
for seed in seeds:
knn.n_neighbors = seed
# Definindo a aleatoriedade dos folds
kf = KFold(n_splits=folds,
shuffle=True,
random_state=seed)
scores = cross_validate(algorithm,
X,
y,
cv=kf,
scoring=scoring_names)
Resultados obtidos
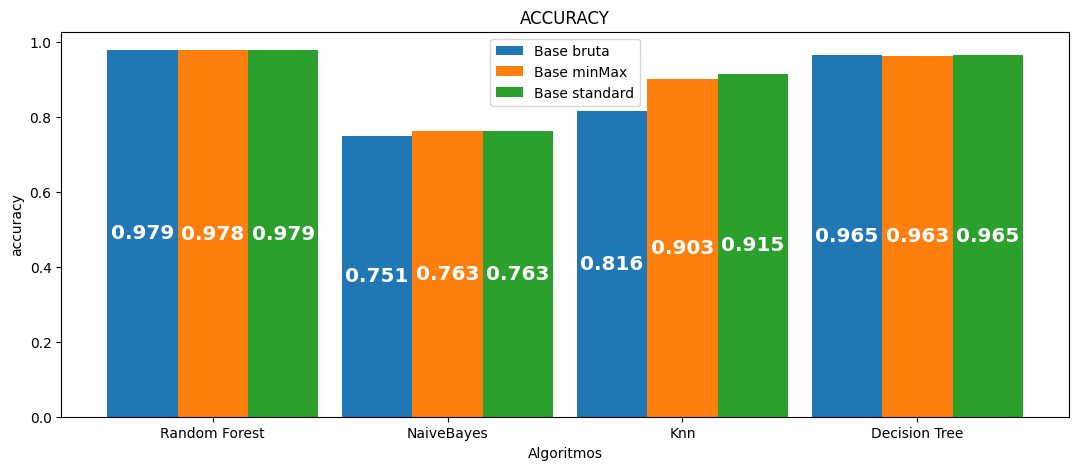
Base bruta
Tempo total: 38 minutos
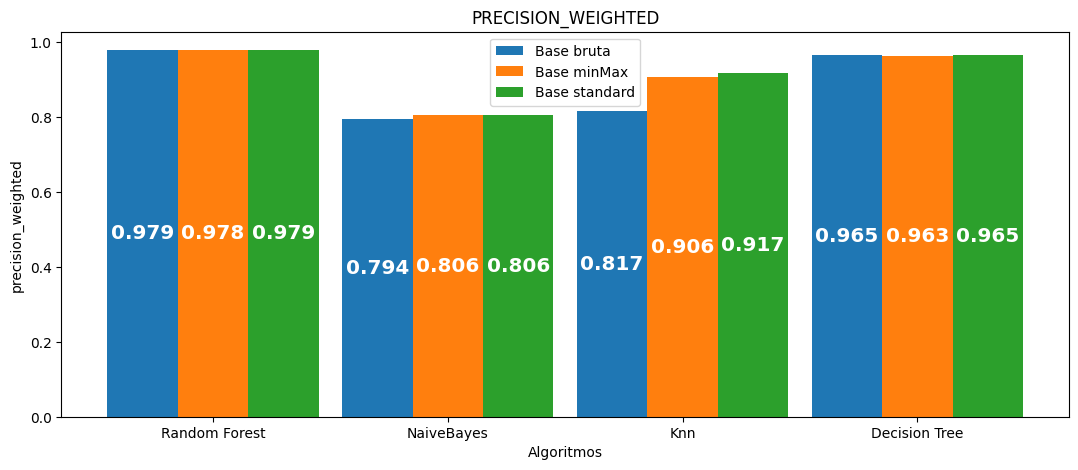
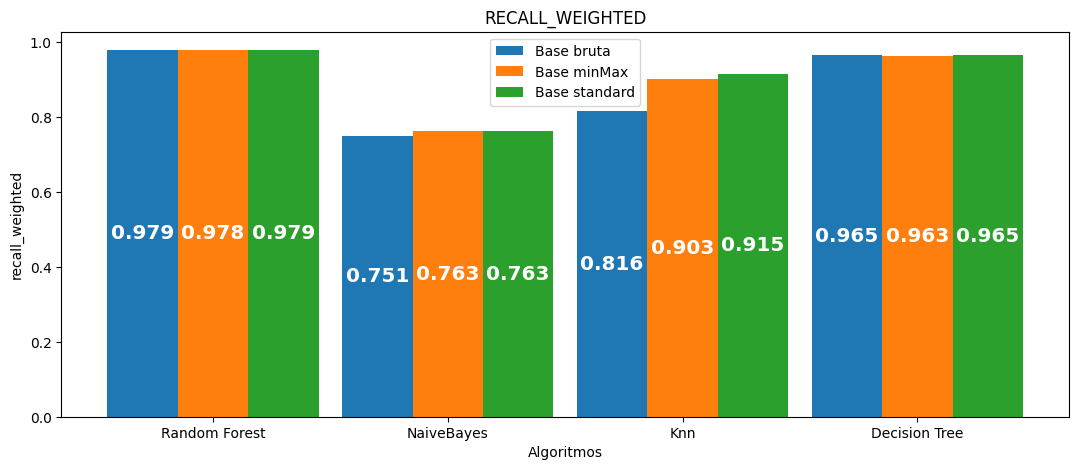
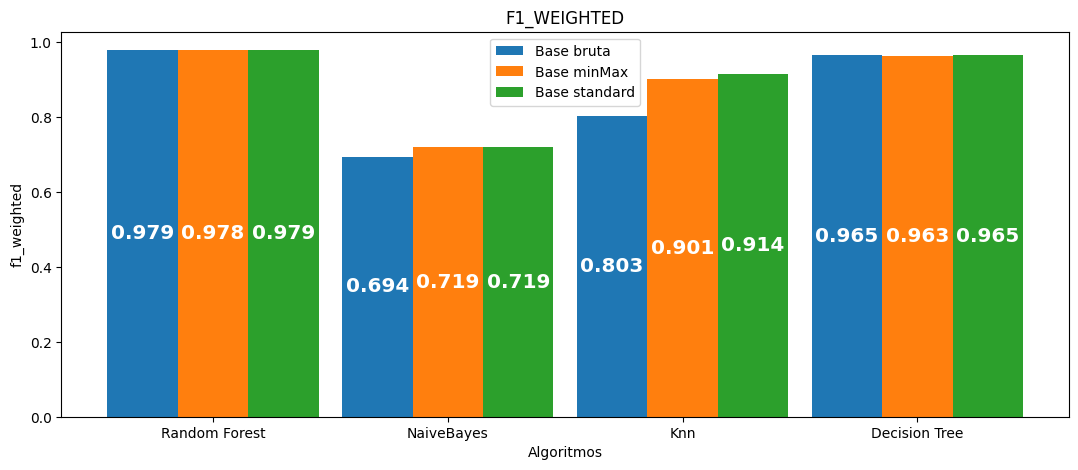
| Algoritmo | Acurácia média | Precisão média | Recall médio | F1 médio | Tempo médio por seed | Tempo total |
|---|---|---|---|---|---|---|
| Random Forest | 0.978829 | 0.978726 | 0.978829 | 0.978694 | 416.122 | 2080.612 |
| NaiveBayes | 0.750596 | 0.794417 | 0.750596 | 0.694432 | 3.377 | 16.886 |
| Knn | 0.816218 | 0.816819 | 0.816218 | 0.802933 | 14.091 | 70.453 |
| Decision Tree | 0.964801 | 0.964881 | 0.964801 | 0.964835 | 23.168 | 115.840 |
Base MinMax
Tempo total: 35 minutos
| Algoritmo | Acurácia média | Precisão média | Recall médio | F1 médio | Tempo médio por seed | Tempo total |
|---|---|---|---|---|---|---|
| Random Forest | 0.977769 | 0.977657 | 0.977769 | 0.977631 | 379.574 | 1897.870 |
| NaiveBayes | 0.763092 | 0.805737 | 0.763092 | 0.718866 | 3.573 | 17.865 |
| Knn | 0.902516 | 0.905992 | 0.902516 | 0.901157 | 17.304 | 86.521 |
| Decision Tree | 0.963368 | 0.963447 | 0.963368 | 0.963400 | 22.341 | 111.706 |
Base Standard
Tempo total: 38 minutos
| Algoritmo | Acurácia média | Precisão média | Recall médio | F1 médio | Tempo médio por seed | Tempo total |
|---|---|---|---|---|---|---|
| Random Forest | 0.978767 | 0.978663 | 0.978767 | 0.978632 | 414.971 | 2074.855 |
| NaiveBayes | 0.763260 | 0.805852 | 0.763260 | 0.719109 | 3.366 | 16.828 |
| Knn | 0.914789 | 0.916956 | 0.914789 | 0.913899 | 20.085 | 100.425 |
| Decision Tree | 0.964659 | 0.964744 | 0.964659 | 0.964694 | 23.172 | 115.859 |
Acurácia:
Precisão (média):
Recall (média):
F1 (média):
Considerações Finais
Sobre as bases:
- O pré-processamento minMax precisou de menos tempo para toda a execução.
- A base bruta teve resultados consideravelmente inferiores nos algoritmos Naive Bayes e KNN.
- A diferença de resultados entre a base minMax e standard só foi notória (ainda que pouco) no KNN.
- Algoritmos baseados em árvores de decisão tiveram resultado similar entre a base bruta e a standard. Enquanto a minMax teve resultados um pouco inferiores
Sobre os algoritmos:
- Algoritmos baseados em árvores de decisão (RF, DT) mantiveram quase os mesmos resultados entre as bases.
- O KNN foi o mais afetado negativamente com a falta de um pré-processamento
Referências
- BAQUI, P. O.; MARRA, V.; CASARINI, L.; ANGULO, R.; DÍAZ-GARCÍA, L. A.; HERNÁNDEZ-MONTEAGUDO, C.; LOPES, P. A. A.; LÓPEZ-SANJUAN, C.; MUNIESA, D.; PLACCO, V. M.; QUARTIN, M.; QUEIROZ, C.; SOBRAL, D.; SOLANO, E.; TEMPEL, E.; VARELA, J.; VÍLCHEZ, J. M.; ABRAMO, R.; ALCANIZ, J.; … TAYLOR, K. The miniJPAS survey: star-galaxy classification using machine learning. Astronomy & Astrophysics. [S. l.]: EDP Sciences, jan. 2021. DOI 10.1051/0004-6361/202038986. Disponível em: http://dx.doi.org/10.1051/0004-6361/202038986
- CHAO, Li; WEN-HUI, Zhang; JI-MING, Lin. Study of Star/Galaxy Classification Based on the XGBoost Algorithm. Chinese Astronomy and Astrophysics. [S. l.]: Elsevier BV, out. 2019. DOI 10.1016/j.chinastron.2019.11.005. Disponível em: http://dx.doi.org/10.1016/j.chinastron.2019.11.005.
- NOLTE, Aleke; WANG, Lingyu; BILICKI, Maciej; HOLWERDA, Benne; BIEHL, Michael. Galaxy classification: A machine learning analysis of GAMA catalogue data. Neurocomputing. [S. l.]: Elsevier BV, maio 2019. DOI 10.1016/j.neucom.2018.12.076. Disponível em: http://dx.doi.org/10.1016/j.neucom.2018.12.076.
- CLARKE, A. O.; SCAIFE, A. M. M.; GREENHALGH, R.; GRIGUTA, V. Identifying galaxies, quasars, and stars with machine learning: A new catalogue of classifications for 111 million SDSS sources without spectra. Astronomy & Astrophysics. [S. l.]: EDP Sciences, jul. 2020. DOI 10.1051/0004-6361/201936770. Disponível em: http://dx.doi.org/10.1051/0004-6361/201936770.